2026年4月:AI切割助手技术科普,从手动抠图到SAM“听懂人话”
如果你经常做图片编辑,一定对“抠图”这件事深有感触——用Photoshop的魔棒工具一点点选中边界、手动调整边缘羽化,碰上发丝、半透明材质或复杂背景,往往得花上十几分钟甚至更久。而今天要聊的“AI切割助手”,正是利用人工智能技术让计算机自动理解图像中哪些像素属于前景、哪些属于背景,实现一键抠图、一键分割的强大工具。它是计算机视觉领域最核心的底层技术之一,支撑着从美颜修图到自动驾驶、从医疗影像分析到工业质检的无数实际应用。本文将从传统方案的痛点出发,由浅入深讲解图像分割的核心概念、底层原理与典型代码实现,并附上高频面试题,帮你真正理解这个热门方向。
一、痛点切入:为什么需要AI切割助手?
在没有AI辅助的时代,图像分割主要依赖传统图像处理算法。以最简单的基于阈值的分割为例:
import cv2import numpy as np img = cv2.imread('cat.jpg', 0) _, binary = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) cv2.imwrite('segmented.jpg', binary)
这段代码的核心逻辑是:把灰度值大于127的像素设为白色(前景),小于127的设为黑色(背景)。
传统方案的核心痛点:
效果单一:阈值法只适用于前景背景灰度差异明显(如白纸黑字)的场景,一旦光线不均或颜色相近,分割结果几乎不可用。
泛化能力弱:换一张不同光照或背景的图片,参数必须重新调试。
无法处理复杂场景:发丝、半透明材质、动态模糊等细节,传统算法完全无能为力。
交互成本高:专业设计师用Photoshop手动抠一张复杂人像,耗时可能超过30分钟。
AI切割助手的设计初衷:用深度学习模型学习“什么是前景、什么是背景”的通用规律,从而实现零样本分割——不需要人工标注,模型见到任何新图像都能自动理解并完成切割。
二、核心概念讲解:语义分割
语义分割(Semantic Segmentation) 是图像分割中最基础的概念。其英文全称是 Semantic Segmentation,核心目标是将图像中的每个像素分配一个类别标签(如“猫”“天空”“草地”),输出一张与输入图像尺寸相同的标签图-。
通俗理解:可以把语义分割想象成给图像上色——属于“猫”的像素涂成红色,属于“天空”的像素涂成蓝色,属于“草”的像素涂成绿色,不同类别之间用不同颜色区分。
生活化类比:就像给一幅黑白线稿涂色,涂色规则是“同一个对象用同一种颜色”。语义分割模型做的正是这件事——自动识别图像中每个区域是什么东西,然后“涂上”对应的颜色。
核心作用:语义分割的价值在于提供像素级的精细理解。例如自动驾驶中,车辆需要知道路面上的每一个像素是属于“行人”“车辆”还是“道路”,才能做出准确的驾驶决策。
三、关联概念讲解:实例分割
实例分割(Instance Segmentation) 的英文全称是 Instance Segmentation。它不仅要像语义分割那样区分像素类别,还要区分同一类别的不同个体——给图像中每一只猫、每一个人分配独立的实例ID-。
概念关系:语义分割回答的是“这个像素是什么”,实例分割回答的是“这个像素属于哪个具体物体”。两者同属于图像分割的技术范畴,但实例分割是语义分割的精细化升级。
简单示例:下图中,语义分割会把两只猫的所有像素都标记为“猫”(一个颜色),而实例分割会把左边那只猫标记为“猫1”、右边那只标记为“猫2”——区分得一清二楚。
全景分割(Panoptic Segmentation) 则更进一步:既区分不同实例,又把背景区域(如天空、草地)作为“stuff”类别整体处理,不区分具体实例-。
四、概念关系与区别总结
| 对比维度 | 语义分割 | 实例分割 |
|---|---|---|
| 输出形式 | 每个像素一个类别标签 | 每个像素:类别标签 + 实例ID |
| 是否区分同类个体 | ❌ 不区分 | ✅ 区分 |
| 典型应用 | 自动驾驶道路分割 | 医学影像中的细胞分割、人群计数 |
| 一句话记忆 | “这是猫” | “这是猫1,那是猫2” |
核心逻辑关系总结:语义分割解决“是什么”,实例分割解决“谁是谁” ——后者是前者的精细化扩展。
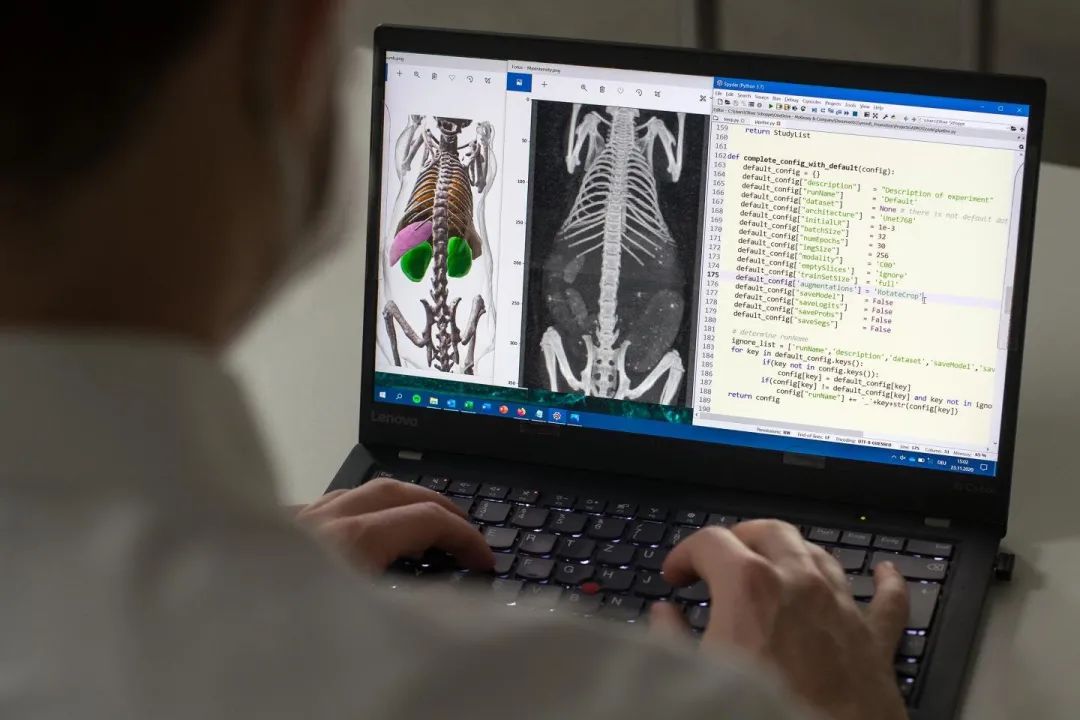
五、代码示例:用SAM 2实现AI智能切割
Meta在2024年7月发布了SAM 2(Segment Anything Model 2),在SAM 1的基础上支持实时、可提示的对象分割,将图像和视频分割功能统一到一个强大系统中-2。下面是一个极简示例,展示如何用几行代码完成AI智能切割:
import torch from segment_anything import sam_model_registry, SamAutomaticMaskGenerator 1. 加载预训练模型(推荐使用ViT-H版本,参数量14亿) sam = sam_model_registry["default"](checkpoint="sam_vit_h_4b8939.pth") sam.to(device="cuda") SAM模型较大,建议GPU显存≥16GB 2. 创建自动掩码生成器(零样本,无需人工提示) mask_generator = SamAutomaticMaskGenerator(sam) 3. 输入任意图像,自动生成所有物体的分割掩码 masks = mask_generator.generate("street_view.jpg") 4. masks是一个字典列表,每个字典包含: - segmentation: 掩码数组(bool类型) - area: 区域面积 - bbox: 边界框坐标 - predicted_iou: 模型预测的IoU置信度 for mask in masks: print(f"检测到物体,面积:{mask['area']},置信度:{mask['predicted_iou']:.2f}")
关键步骤注释:
加载预训练模型:SAM有ViT-H(14亿参数)和ViT-L(6亿参数)两种规模,更大参数意味着更强的分割能力-29。
自动掩码生成器:这是SAM最强大的功能之一——不需要点、框等人工提示,模型自动发现并分割图像中的所有物体。
输出解析:每个掩码字典包含了分割区域的位置、大小和置信度信息。
六、前沿进展:从SAM到“听懂人话”的SAM 3
2025年10月,Meta的下一代模型SAM 3(Segment Anything Model 3) 悄悄现身ICLR 2026盲审论文,带来了革命性升级——可提示概念分割(Promptable Concept Segmentation, PCS) -2。
SAM 3的核心创新:不再需要用户手动点击或用框圈出物体,而是可以直接输入短名词短语(如“黄色校车”“条纹猫”)或图像范例,模型就能自动在图像或视频中找到并分割出所有匹配的对象-4。
简单来说:SAM 1和SAM 2让用户“手动一个个点出来”,SAM 3则进化到“告诉模型一个概念,它帮你全部找出来”-2。
性能数据:在提出的新基准SA-Co上,SAM 3的性能比此前系统提升了至少2倍;在LVIS数据集上,零样本掩码平均精度达到47.0,而此前最佳纪录是38.5-2。速度方面,单张H200 GPU处理超过100个物体的图像仅需30毫秒-2。
七、底层原理:SAM的技术架构
SAM的技术架构可以拆解为数据引擎、模型架构、交互接口三个层次-29:
数据引擎(Data Engine) :SAM的训练依赖于Meta构建的SA-1B数据集,包含1100万张图像和10亿个掩码(Mask)。采用“模型生成→人工修正”的交互式标注模式,大幅降低了标注成本-29。
模型架构(Model Architecture) :基于Vision Transformer(ViT) ,具体为ViT-H(14亿参数)和ViT-L(6亿参数)两种规模。输入为图像 + 提示点/框/掩码,输出为分割掩码-29。
底层依赖技术:SAM的强大功能深度依赖自注意力机制(Self-Attention) 与Transformer架构——正是这两个底层技术让模型能够捕捉图像中任意像素之间的长距离依赖关系,实现“分割一切”的能力。
SAM 3的架构升级:采用DETR风格检测器 + SAM 2 Transformer跟踪器的混合架构,基于共享的感知编码器(Perception Encoder) 统一处理图像、文本和图像示例的特征-30。核心创新是“解耦识别与定位” ——用一个“存在头”(Presence Head)先判断概念是否存在,再精确定位,大幅提升了在歧义类别上的准确性-30。
八、高频面试题与参考答案
Q1:图像分割、目标检测和图像识别有什么区别?
参考答案:
图像识别(分类) :回答“这张图里有什么?” → 输出一个类别标签(如“猫”)
目标检测:回答“有什么,在哪?” → 输出多个边界框 + 类别标签(如“猫在左上角”)
图像分割:回答“每个像素属于什么?” → 输出像素级的分类结果,精度最高-
Q2:语义分割和实例分割的区别是什么?
参考答案:
语义分割:只区分像素属于什么类别,不区分同一类别的不同个体(如两只猫的所有像素都标记为“猫”)
实例分割:在语义分割的基础上,为同一类别的每个独立物体分配唯一ID(如“猫1”“猫2”)
一句话记忆:语义分割解决“是什么”,实例分割解决“谁是谁”
Q3:SAM模型的“零样本分割”能力是如何实现的?
参考答案:
基于1100万张图像、10亿个掩码的超大规模预训练,让模型学习到通用的物体边界特征-29
采用Vision Transformer架构,通过自注意力机制捕捉图像中任意像素之间的长距离依赖关系-29
支持点、框、掩码等多种提示方式,无需针对新类别重新训练即可分割未见过的物体-29
输出掩码的同时给出置信度分数,辅助决策-29
Q4:SAM 3相比SAM 2有哪些核心突破?
参考答案:
从视觉提示升级到概念提示:支持输入短名词短语(如“黄色校车”),让模型自动找全所有匹配实例-4
性能大幅提升:在PCS任务上实现2倍性能提升,LVIS数据集零样本掩码AP达到47.0-2
速度优化:处理超100个物体的图像仅需30毫秒(H200 GPU)-2
支持视频:统一了图像和视频的分割能力,可处理≤30秒的短视频-4
Q5:训练SAM模型的核心挑战是什么?
参考答案:
数据标注成本极高:像素级标注一张医学影像可能需要资深医生花费数小时-1
泛化能力不足:传统方法难以适应训练集中未见过的新类别-1
计算资源需求大:ViT-H(14亿参数)需要GPU显存≥16GB才能流畅推理-29
SAM通过交互式数据引擎(模型生成+人工修正)和超大规模预训练,有效缓解了上述挑战-29
九、结尾总结
回顾全文,我们从传统抠图的痛点出发,梳理了图像分割领域的核心知识链路:
核心概念:语义分割(像素级分类)与实例分割(区分同类个体)的区别与联系
实践层面:SAM 2仅需几行Python代码即可完成零样本分割
前沿进展:SAM 3引入“概念提示”,从“手动点出来”升级到“说出概念就自动找全”
底层原理:Vision Transformer + 自注意力机制 + 10亿掩码大规模预训练
面试要点:区分图像分类、目标检测、语义分割、实例分割的核心差异
需要特别注意的易错点:很多初学者误以为“语义分割就是目标检测的精细化版本”,这是错误的——两者是不同层次的任务,而非粗细粒度的差异。目标检测输出边界框,语义分割输出像素级分类,不可混为一谈。
下期预告:下一篇将深入剖析SAM 3的“存在头”(Presence Head)设计原理,以及如何用PyTorch从零搭建一个简化版的可提示分割模型,敬请期待!